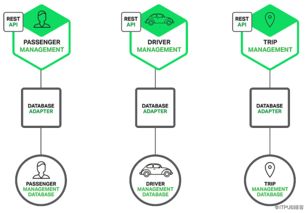
微服务架构是一种将单一应用程序拆分为一组小型、独立的服务的设计风格。这些服务围绕业务能力构建,可以独立部署、扩展和更新,并通过轻量级通信机制(通常是HTTP/REST或消息队列)相互协作。在这种架构中,数据处理服务扮演着至关重要的角色,它专门负责数据的存储、检索、转换、验证和分析,是支撑业务逻辑和数据驱动决策的基础。
数据处理服务在微服务架构中的核心职责包括:
- 数据持久化与管理:提供对数据库(如关系型数据库、NoSQL数据库)或其他存储系统的封装访问,确保数据的完整性和一致性。服务可能实现仓储模式(Repository Pattern),将数据访问逻辑与业务逻辑解耦。
- 数据转换与聚合:从多个源(如其他微服务、外部API)接收数据,进行清洗、格式转换或聚合操作,以满足特定业务需求。例如,一个订单处理服务可能调用用户服务和产品服务的数据,组合生成完整的订单视图。
- 数据验证与业务规则执行:在数据写入或更新前执行验证逻辑,确保数据符合业务规则和约束条件。这有助于维护数据的质量和系统的可靠性。
- 查询与检索优化:提供高效的数据查询接口,可能包括缓存机制(如Redis)、索引优化或特定查询语言的实现,以支持复杂的报表和分析需求。
- 事件驱动与数据同步:在事件驱动的微服务架构中,数据处理服务可能作为事件的生产者或消费者,通过消息队列(如Kafka、RabbitMQ)发布或订阅数据变更事件,实现服务间的最终一致性。
设计数据处理服务时需考虑的关键因素:
- 数据所有权与边界:遵循领域驱动设计(DDD)原则,每个数据处理服务应拥有其领域内的数据,避免跨服务的直接数据库访问,以维护松耦合。
- 数据一致性模型:根据业务场景选择强一致性(如分布式事务)或最终一致性(如通过事件溯源或补偿事务)。在分布式系统中,最终一致性往往更可行。
- 可扩展性与性能:服务应能水平扩展以处理高负载,例如通过分库分表、读写分离或使用云原生数据库服务。异步处理和批量操作可提升性能。
- 安全性:实施数据加密、访问控制和审计日志,确保敏感数据(如用户个人信息)的安全合规。
- 监控与可观测性:集成日志记录、指标收集(如请求延迟、错误率)和分布式追踪,以便快速诊断数据流问题。
典型的数据处理服务示例包括:用户档案服务(管理用户数据)、订单服务(处理交易记录)、库存服务(跟踪商品库存)以及分析服务(聚合数据生成洞察)。这些服务通常通过API网关暴露接口,供前端应用或其他微服务调用。
在微服务生态系统中,精心设计的数据处理服务是实现灵活、可维护和可扩展系统的基石。它不仅是数据的保管者,更是业务逻辑与数据基础设施之间的桥梁,推动着现代应用的高效运作。